本文介绍 Kafka 消费的一个例子,以及如何优化提升消费的并行度。
一个例子
Kafka 消费一般使用 github.com/Shopify/sarama 包实现,现已支持消费组消费。下面是一个消费组消费的例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
func consume(){
// 定义一个消费者,并开始消费
consumer := Consumer{}
ConsumerHighLevel.Consume(ctx, []string{Conf.topic}, &consumer); err != nil {
sarama.Logger.Printf("[ERROR] Error from Consumer: %s", err.Error())
}
}
type Consumer struct {}
func (consumer *Consumer) Setup(sarama.ConsumerGroupSession) error { return nil }
func (consumer *Consumer) Cleanup(sarama.ConsumerGroupSession) error { return nil }
func (consumer *Consumer) ConsumeClaim(session sarama.ConsumerGroupSession, claim sarama.ConsumerGroupClaim) (err error) {
for {
message := <-claim.Messages()
println(message.Value) // 消费逻辑
session.MarkMessage(message, "") // 提交偏移
}
return nil
}
|
Client 支持并行消费多个Topic。消费时,会针对各Partition分别启动一个ConsumeClaim 的goroutine,获取队列数据并消费。如下图所示:
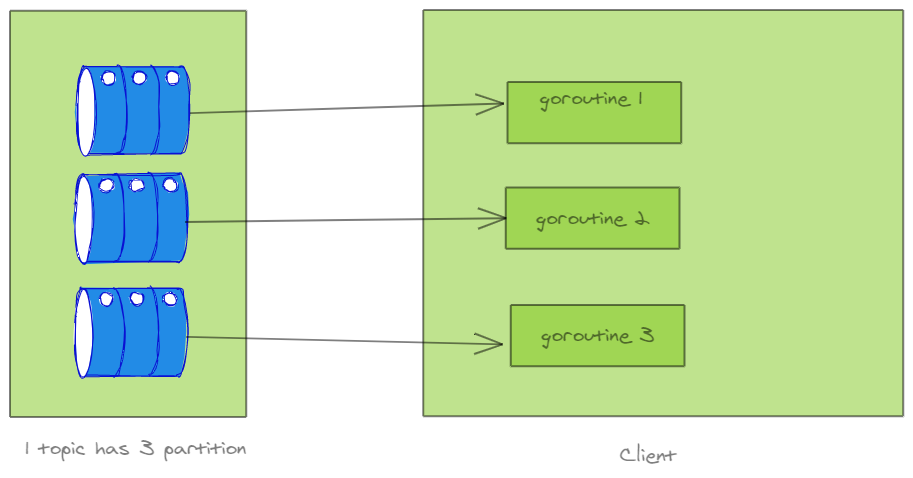 每个goroutine 会标记消息的偏移量,以方便提交偏移至远程。当服务关闭重启后,会从远端获取当前消费的偏移,并继续消费。
每个goroutine 会标记消息的偏移量,以方便提交偏移至远程。当服务关闭重启后,会从远端获取当前消费的偏移,并继续消费。
存在的问题
为保证消费消息的顺序性,需一个队列由一个 goroutine 消费。此模式下并行度则由kafka的队列数量来控制。Kafka 队列数量多,并行度就越大,队列数越少,并行度就小。
假设每条消息需要处理的时间平均为10ms,则一个队列的最大消费个数就是100/s;设置32分片,可以达到3200/s的消息处理量。当业务增长时,可能需要增加kakfa Topic的分片数量来提升消息处理量了。
但Kafka的分片数量并不能无限增长。因设置太多的分片可能会造成 Broker 选举慢,客户端需要cache 的消息量过大等问题[1]。
下面看看提升并行度的另一种思路。
如何解决
提升并行度的另一种方案,就是在本地做二次Sharding,使用本地队列做真实消费。下面是一个示意图:
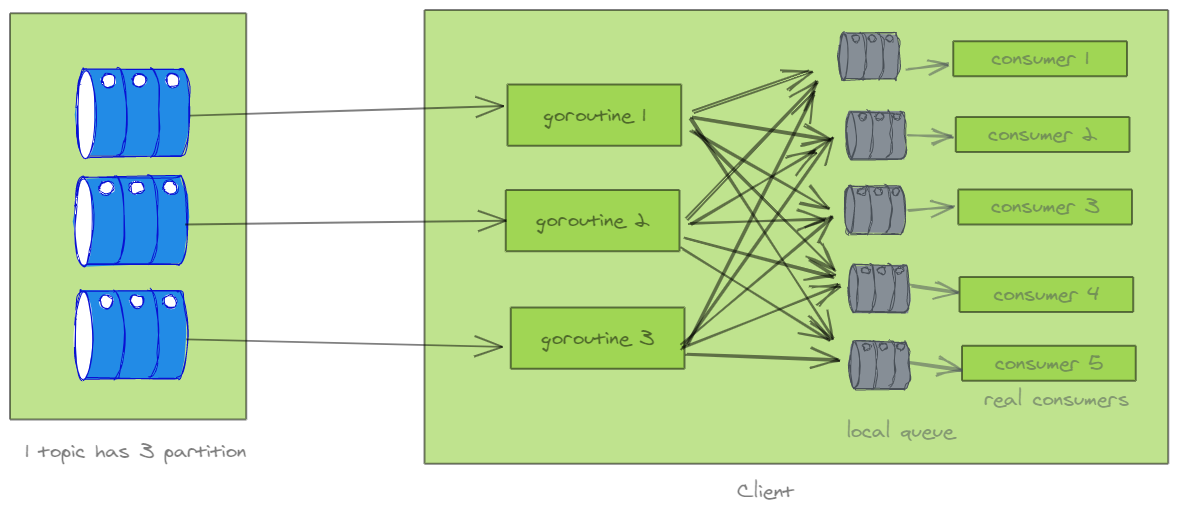
每个goroutine通过分片规则重新分配到多个本地队列中。本地的队列个数(消费goroutine 数量)可以自由控制,使消费的并行度可控。
当然,使用本地队列会有如下几个问题:
如何保证偏移提交的顺序性?
从本地队列中消费完成后,需要提交偏移到远程。如果提交顺序有问题,可能会出现消息漏掉的情况。举个例子:
消息M1,M2 均来自远程队列Q,且 M1 进入队列的时间早于 M2。在本地做分发时,M1 进入 LQ1, M2 进入 LQ2。若 M1 早于 M2 消费完成并提交偏移则没有问题;若 M1 晚于 M2 消费完成并提交了偏移,此时服务异常退出,当再次启动服务时M1 消息将不再被消费,造成M1 消息丢失。为此,需要在本地维护一个偏移提交的逻辑,保证提交偏移的有序性。逻辑如下:
- Kafka 的Offset 并不保证连续性[2],需要对每个kafka Partition 提供一个逻辑队列
waitCommitQueue 保存当前正在消费的消息, 提供一个hashmap waitCommitMap 标记某个偏移已完成消费(偏移较小的消息未消费完成。)
- 当消息从Kafka 队列中取出后,放入
waitCommitQueue队列队尾(标记正在消费),并将消息分发到本地队列。
- 当消息消费完成后,判断该消息是否为
waitCommitQueue 队首:
- 若是,则说明该消息是最小的offset,直接提交。并循环判断队列后面的消息偏移是否已消费完成?
- 如果消费完成,说明可以继续提交偏移
- 如果未消费完成,则需要等待最小消息消费完成。
- 若不是,则在
waitCommitMap中标记已提交,等待最小偏移的消息出现。
下面是一段简要代码片段:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
|
type Consumer struct {
chMessage []chan *CMessage
}
type None struct{}{}
func (consumer *Consumer) ConsumeClaim(session sarama.ConsumerGroupSession, claim sarama.ConsumerGroupClaim) (err error) {
waitCommitQueue := list.New()
waitCommitMap := make(map[int64]None, 100000)
var mutex sync.Mutex
for {
message := <-claim.Messages()
mutex.Lock()
waitCommitQueue.PushBack(message)
mutex.Unlock()
// 自定义的local 队列, 使用channel 实现
// sharding 是自定义的算法
consumer.chMessage[consumer.Sharding(message)] <- &CMessage{
Message: message,
MarkMessage: func() {
mutex.Lock()
defer mutex.Unlock()
if waitCommitQueue.Front().Value.(*sarama.ConsumerMessage).Offset == message.Offset {
waitCommitQueue.Remove(waitCommitQueue.Front())
session.MarkMessage(message, "")
for waitCommitQueue.Len() > 0 {
item := waitCommitQueue.Front()
offset := item.Value.(*sarama.ConsumerMessage).Offset
if _, ok := waitCommitMap[offset]; !ok {
break
}
delete(waitCommitMap, offset)
session.MarkMessage(item.Value.(*sarama.ConsumerMessage), "")
waitCommitQueue.Remove(item)
}
} else {
waitCommitMap[message.Offset] = None{}
}
},
}
}
}
|
在做消费时,仅需要启动协程,分别消费各个channel中的数据即可:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
func (consumer *Consumer) consume(){
queues := consumer.chMessage
for i := 0; i < len(queues); i++ {
wg.Add(1)
go func(queue chan *kafkautils.CMessage) {
defer wg.Done()
for {
select {
case message := <-queue:
// time.Sleep(100 * time.Millisecond)
time.Sleep(time.Duration(rand.Int() % 20) * time.Millisecond)
message.MarkMessage()
atomic.AddInt32(&count, 1)
case <-closed:
return
}
}
}(queues[i])
}
}
|
有了本地队列的加持,决定并行度的不再是远端队列数量,而是本地的消费队列数量,只要多开点channel,所有问题将迎刃而解。
如何保证本地队列不会暴涨导致OOM?
使用带缓冲的channel 作为本地队列,当队列满后将阻塞。避免了无限制的增长导致OOM.
应用场景
- 适合于消费端消费慢,并行度过低的情况。如果通过增加一些kafka 的partition 的方式解决,建议直接用kafka 的partition,避免在消费端增加逻辑复杂度。
- 消费的消息具有区分度,可以通过某些字段做分片。
- 当然此类消费逻辑也适合于消息聚合的场景,通过调整本地消费队列的个数,减少消费的并行度,一定程度上降低消费的速度和服务器的负载。
- 当服务宕机或者出现故障重启后,可能会出现重复消费的情况。因此消息需要保障最终一致性。
其他
还有个问题,为什么不是每个kafka 队列对应独立的协程池,而是公用同一个协程池?
通过公用协程池,可以实现资源公用,针对消费写入速度相差甚远的队列时,可以取长补短。
本文相关代码转到github查看
引用