Golang 的内存泄漏
Golang 作为一个提供了GC的语言,还能有内存泄漏一说?其实不然,Go 服务宕机80%应该是因为内存泄漏的缘故了。
导言
内存泄漏 (Memory Leak) 是在计算机科学中,由于疏忽或错误造成程序未能释放已经不再使用的内存。内存泄漏并非指内存在物理上的消失,而是应用程序分配某段内存后,由于设计错误,导致在释放该段内存之前就失去了对该段内存的控制,从而造成了内存的浪费。 (维基百科)
所以,内存泄漏是一个共性的问题。虽然在Golang中提供了聪明的GC操作,但是如果操作不慎,也可能掉入内存泄漏的坑。
什么情况下会内存泄漏
总结了一些经常碰到的内存泄漏的例子,以飨读者:
- 数据泄漏
比如,在全局变量(或者单例模式)中 (例如:map,slice 等 构成的数据池),不断添加新的数据,而不释放。
- goroutine泄漏
goroutine 泄漏,应该是Golang 中经常遇到的一个问题了。由于goroutine 存在栈空间(至少会有2K), 所以goroutine 的泄漏常常导致了golang的内存泄漏。 在官方提供的方法中,如果使用不当,很容易出现goroutine泄漏。比如说:
在 Time 包中:
|
|
由于 NewTicker 和 NewTimer 会创建倒计时发送chan 的协程(创建方法在startTimer 中实现,/src/runtime/time.go),所以这种方法不能多次使用。使用时建议新建 NewTimer 和NewTicker,并控制 Timer 和Ticker 的终结。
再比如说,在 Http 请求时,会返回 *http.Response 对象,Http 响应中的Body是http的响应数据,Body 需要每次读取后关闭。那为什么需要关闭呢,我们从 Body 的赋值代码查找结果:
|
|
从代码中可以看出 resp.Body 实际上仅仅是个代理,我们实际上读取和关闭的是net.Conn 对象。因此也不难看出关闭Body 的意义何在了。(如果不关闭,这个conn 应该是不能关闭的)
除了官方的一些func使用不当会导致goroutine泄漏,日常开发也会碰到各种内存泄漏的例子, 比如说:redis 从连接池取的链接没有做释放,DB 的 stmt 没有关闭等。
如何应对内存泄漏
如果很悲剧,代码上线后,服务发生了内存泄漏,我们可以从几个方面去考虑:
分析goroutine 是否泄漏
从 pprof 的goroutine 分析,是否 goroutine 在持续增长。如果持续增长,那 goroutine 泄漏没跑了。我们用下面的例子来举例。
|
|
上述代码中,逐步创建了1k个goroutine(假定是泄漏的),我们可以通过http://127.0.0.1:8080/debug/pprof/ 访问查看goroutine的变化情况。
a. 在debug 中观察goroutine的数量变化,如果持续增长,那可以确定是goroutine 泄漏了。
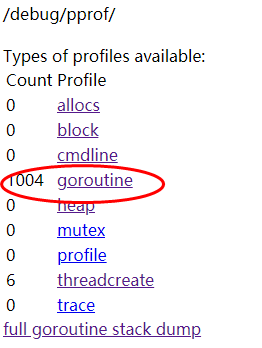
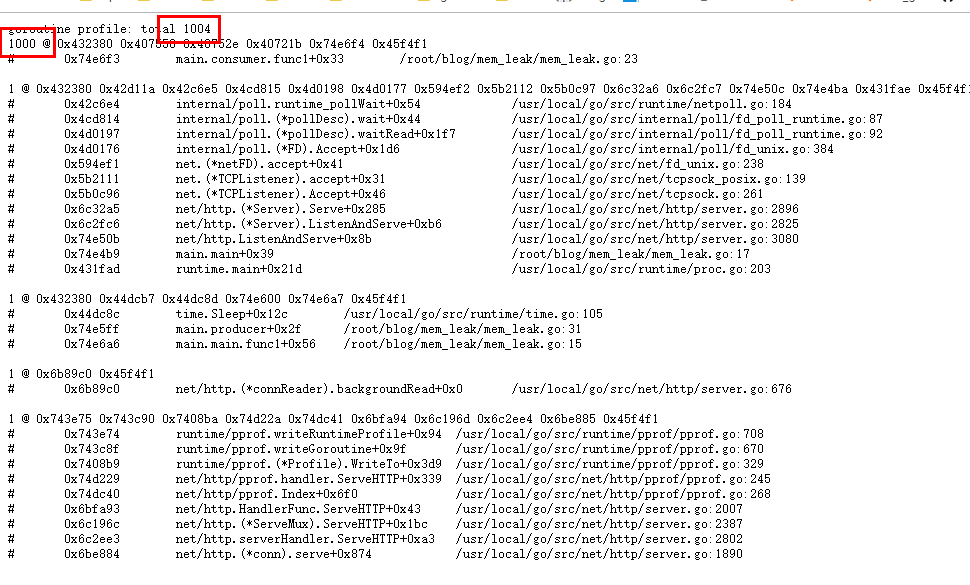
b. 之后访问 http://127.0.0.1:8080/debug/pprof/goroutine?debug=1查看各goroutine数量,查看持续增加的goroutine ,如果存在持续增长的goroutine,那从goroutine的堆栈代码短分析即可。下图中很明显可以看出1K的协程量。(当然是持续增长到达1K的)
数据泄漏怎么看
数据泄漏出现的问题就比较多了,比如长的 string,slice 数据用切片的方式被引用,如果切片后的数据不释放,长的string,slice 是不会被释放的, 当然这种泄漏比较小。下面举一个前两天网友提供的一个案例。
|
|
例子比较简单,从net Accept 数据,并开启一个goroutine 做数据处理。singals 呢,用于做事件处理,每接收一个链接,给singal 推一条数据。 为了从中查找内存泄漏,我们也增加了pprof。
为了能尽快发现问题,我这边用了一个简单的shell对服务施压(请求2w http 服务,不关心请求返回结果)。命令如下:
|
|
从pprof 的 heap 中,我们能轻易的发现:
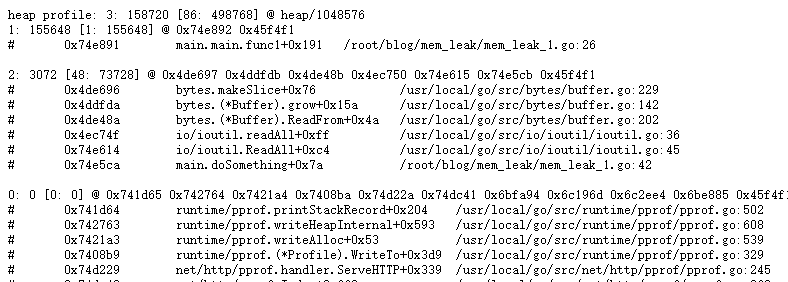
内存分配中,mem_leak文件的26行(append) 操作 申请的内存排在了top 1,仔细看代码,发现我们slice中的数据从来没有释放,所以造成了上面的问题。
如何解决这个问题呢? 其实比较简单。只需要将slice,修改成带cache的chan(作为一个队列来使用),当数据使用过后即可销毁。不仅不会再出现内存泄漏,也保证了功能上的一致性。(当然需要重新起一个协程, 由于上面的for 是阻塞的,不会断开,所以也导致了下面的slice 不工作)
做一个小结
当然,上面的例子都是精简到不能再精简的小例子,实际中遇到的问题可能会要比这个复杂的多。但是万变不离其宗,找到正确的方法解决也不是什么难事。
除了上面的一些问题,还应该注意点什么,做了下面的总结:
- 做一个服务进程内存监控的报警,这个很有必要,也是正常服务应该做的。
- pprof 提供的是堆上的监控,栈内存很少会泄漏,也不容易被监控。
- 尽量在方法返回时不要让使用者去操作Close,减少goroutine泄漏的可能。
- 在用全局的Map,Slice 时要反复考虑导致内存泄漏。
- slice 引用大切片时,考虑会不会有不释放的可能性。
才疏学浅,有问题请留言。谢谢
![]()